Duplicate content can be a headache for your website’s SEO performance and reputation. When similar content appears on multiple websites, search engines struggle to rank that webpage. This hampers your site’s trust signal of your site and reduces the chance of appearing in search results.
The rel=”canonical” tag is a simple yet effective way to fix the duplicate content appearance issue. This HTML element lets search engines differentiate between the original and duplicate content. As a result, your content gets the search engine exposure, and your site earns authority.
In this article, we will explore what the canonical tag is, its importance, and its effective usage. Ultimately, you’ll learn how to prevent duplicate content issues to climb the SEO ladder.
Table of Contents
Common Causes of Duplicate Content
Duplicate content is a substantial block of text, or the entire page, that comes up in several web addresses. This means you can see duplicate content on a single website or across different websites. Here are some common causes of duplicate content:

Same Content but Multiple URLS: Your website may link to similar content in multiple URLs. For example, a product page may show up with the same link, such as www.example.com/product and www.example.com/product/ref=123.
URL Parameters and Session IDs: URL parameters allow you to track user sessions or filter products in eCommerce websites. These parameters can create different URLs for the same page.
Syndicate Content and Content Scraping: Let’s say someone has scraped your content or simply republished it without your permission. This can happen when new articles and posts are shared within different domains.
Printer-friendly versions: When preparing printer-friendly versions of pages, duplicate content can appear. Thus, you need proper content management to prevent duplicate content from appearing on your site.
Applying the rel=”canonical” tag and understanding these causes will help you prevent duplicate content before duplicate content issues occur.
Why is Duplicate Content a Problem for SEO?
The main issue with duplicate content is confusion for the search engine while ranking. It negatively impacts your website in different areas, such as:

Weak Search Rankings: When a search engine finds duplicate content in multiple resources, it becomes confused and struggles to decide whether to rank it. The ranking signals spread to multiple pages instead of yours only, reducing your content’s visibility and ranking opportunity.
Waste of Crawl Budget: Search engines crawl your website within a limited time and budget. So, you miss the opportunity to get a search engine appearance for other pages when it repeatedly crawls the same content.
Search Result Confusion: Duplicate content with multiple versions may appear in search results. This confuses the visitors and leads them to websites with lower authority and trust signals. Ultimately, the website with the original content loses traffic due to confusion.
Risk of Content Cannibalization: Your web pages will compete with each other if they contain similar keywords. This issue, known as keyword cannibalization, will jeopardize your SEO strategy.
For example, let’s say a blog article is available at:
- https://example.com/blog/article-1
- https://example.com/blog/article-1-print
Without cannibalization, both contents will end up competing for the same queries. As a result, your primary content will lose ranking opportunities.
Though content duplication is not always intentional, it can damage your site’s SEO and reputation. This is where rel=”canonical” is an effective solution to minimize SEO challenges.
What is rel=”canonical”?
The rel=”canonical” tag is an HTML element that helps search engines discover the genuine version of a webpage. This tag helps search engines skip duplicate content and identify the one with a canonical tag. Thus, the original content gets indexed and has a satisfying ranking in search engine result pages.
Here’s what a canonical tag looks like in HTML:
You need to include this tag within the section of a webpage that includes the content. This element communicates with the search engines and says this is the actual URL for the content.
For example, suppose your website has two URLs for the same product:
- https://example.com/product?color=red
- https://example.com/product
Search engines will count these as separate pages if you haven’t included the canonical tag on both pages. By adding the tag to both web pages, you are pointing them to the main URL : (https://example.com/product). This allows you to solidify the ranking signals for the actual content that will appear in the search results.
When to Use rel=”canonical” tag?
You must use the rel=”canonical” tag to prevent someone from duplicating your content. It also helps you sort out the primary content if there is duplicate content on your website. Here are the scenarios where using this tag becomes mandatory:
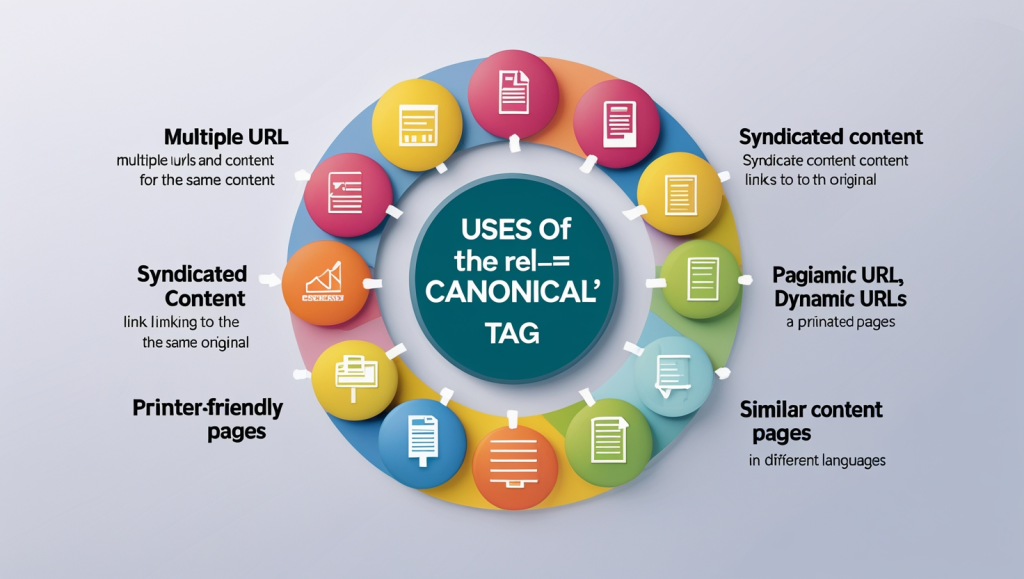
Multiple URLs With the Same Content
Duplicate or almost similar pages often occur via session IDs, URL parameters, or different tracking codes.
Example:
- https://example.com/product?color=red
- https://example.com/product?utm_source=newsletter
In this scenario, you can add a canonical tag that indicates the main version: https://example.com/product. Thus, the search engine receives the signal from you about which URL to focus on
Content Syndication Across Websites
It takes a significant amount of time and effort to create content that ranks. Think about how it will feel when someone who duplicates your content gets a higher position in search engine results.
However, you can add the canonical tag if the republished page is on a partner website. This tag should return to the original URL to ensure your site receives the ranking benefits.
Paginated Content
Your blog or eCommerce store most probably has multiple pages. Search engines may treat these pages as duplicate content. However, you can resolve this issue by simply adding a canonical tag to point to the original page or category page.
Dynamic URLs
Search engine result pages, filtered sites or pages, and eCommerce businesses utilize dynamic URLs. There are certain filter combinations like the following:
- https://example.com/category?filter=size-large
- https://example.com/category?filter=size-large&sort=price
Adding a canonical tag that indicates the main category page strengthens the SEO signals and removes confusion.
Printer-Friendly or Alternate Page Versions
The printer-friendly version of a page can also be the reason behind content duplication. Here is an example:
- https://example.com/article
- https://example.com/article/print
Implement the rel=”canonical” tag on the print version to point to the main article to resolve this issue.
Similar Content Across Language
You may have similar content published in different languages for international audiences. For example:
- example.com/uk
- example.com/us
In this scenario, you need to use and combine canonical tags with hreflang attributes. This allows search engines to understand relationships between pages in different languages.
As you can see, the sole purpose of the rel=”canonical” tag is to guide search engines to the correct URL.
How to Implement rel=”canonical” on Your Website
Implementing the rel=”canonical” tag is a simple yet effective process to maintain your site’s SEO. In this way, you help search engines understand which version of a page should be in focus. Here’s a step-by-step approach to implementing canonical tags:
Identify Duplicate or Similar Content
First of all, identify the duplicate content in your site before implementing the rel=”canonical” tag. Use one of the following tools to identify duplicate content:
- Google Search Console: Check for duplicate URLs under the coverage report.
- Screaming Frog or Sitebulb: Crawl your site to detect pages with similar content or duplicate titles and meta descriptions.
- SEMrush or Ahrefs: Analyze duplicate content across your site and external domains.
Select a set of duplicate pages and choose the ones that you want search engines to consider. The search engine will then consider that content as the primary and authoritative source. You can focus on the original pages that have the most backlinks and traffic.
Add the Canonical Tag in the HTML
You can insert the rel=”canonical” tag in the
section of your preferred webpage. For example:
Now, replace the https://www.example.com/preferred-page-url with your preferred canonical page URL.
Use Canonical Tags Across Duplicate Pages
You can add the rel=”canonical” tag in each duplicate page that you come across. It should all point to the main URL of the content. For example:
- Duplicate URLs: https://example.com/page?filter=size
- Canonical URL: https://example.com/page
The canonical tag should look like this on all duplicate pages:
Test and Validate Your Canonical Tags
Now, you need to ensure that the canonical tags are working effectively. These are the steps you need to follow:
- Go to Google Search Console and inspect the canonical URL for a page. Then, verify whether it matches the preferred URL.
- You can utilize browser developer tools to verify the section to check the correct canonical tag.
- Test your implementation with tools like Screaming Frog or Sitebulb. These tools will help you confirm that the canonical tag is effective and recognized.
Monitor and Troubleshoot Post-Implementation
This is the last step, where you need to monitor your site’s performance. This will help you ensure the canonical tags are working as intended:
- Monitor organic search rankings for the canonical URLs.
- Check for errors or warnings in the Google Search Console regarding canonical tags.
- Adjust the canonical tags whenever you restructure or update your website.
Correct Implementation of rel=”canonical” Tag
Checkout the following examples to learn about the correct implementation of the canonical tag:
Product Pages of eCommerce Stores:
Let’s say you have a product page with two URLs:
- https://example.com/product-blue
- https://example.com/product?color=blue
Now, include the canonical tag to both versions that indicates the primary URL:
Blog Posts with Syndicated Content:
Let’s say one of your blog posts is republished on another site. Thus, you make sure that your original post has a canonical tag pointing to itself. For instance:
- Original URL: https://www.example.com/original-post, include:
- Canonical URL:
Now, you can successfully implement rel=”canonical” tags on your website. It will be easier for you to mitigate duplicate content issues and improve your SEO rankings.
However, if you use WordPress, we recommend plugins like Yoast SEO and Rank Math. These plugins enable you to set canonical URLs for posts and pages without editing the code.
Common Mistakes to Avoid When Using rel=”canonical”
Obviously, the rel=” canonical” tag can resolve major SEO issues when it comes to duplicate content. But mistakes can lead to an SEO disaster on your site rather than fixing it. Here are the things to avoid:
Pointing to the Wrong URL: The canonical tag should only point to the correct primary page. Otherwise, it can confuse the search engine and harm your site’s search engine ranking.
Using Relative URLs: Using absolute URLs (e.g., https://example.com/page) in canonical tags helps you avoid misreading the pages by search engines.
Canonicalizing to the Homepage: Don’t point all pages to the homepage since it directs all the ranking signals to the homepage. Instead, implement a canonical tag only on the relevant primary page.
Not Updating Canonical Tags: When updating your site, remember to update the canonical tags to reflect the new structure. Failure to do so can lead to indexing errors and ranking loss.
Overusing Canonical Tags: Avoid overusing canonical tags for unique content that doesn’t need them. Overusing this tag can also lead to indexing errors and a downfall in SEO ranking.
Properly using the rel=”canonical” tag will help you avoid these mistakes and climb the SEO ladder.
Final Words
Using the rel=”canonical” tag is the best option for maintaining SEO ranking by skipping duplicate content. It helps search engines consider the correct web pages and showcase them in search engine result pages. Moreover, it avoids ranking dilution, improves crawl efficiency, and boosts overall SEO performance.
We recommend auditing your content today and ensuring your site is fully optimized for success.